Several years ago, while scrolling through YouTube, I came across a video of Paul Rudd playing something called “Quantum Chess.” I had no idea what it was, nor did I know that it would become one of the most gloriously nerdy rabbit holes I would ever fall into (see: 5D Chess with Multiverse Time Travel).
Over time, I tried to teach myself how to play these multi-layered, multi-dimensional games, but progress was slow. However, while taking a break during a piano lesson last year, I mentioned to my teacher my growing interest in unnecessarily stressful versions of chess. She told me that she happened to be friends with Dr. Xie Chen, professor of theoretical physics at Caltech who was sponsoring a Quantum Gaming project. I immediately jumped at the opportunity to connect with her, and within days was able to have my first online meeting with Dr. Chen. Soon after, I got invited to join the project. Following my introduction to the team, I started reading “Quantum Computation and Quantum Information”, which helped me understand how the theory behind the games worked. When I felt ready, Dr. Chen referred me to Dr. Spiros Michalakis at Caltech, who, funnily enough, was the creator of the quantum chess video.&
I would’ve never imagined that I am two degrees of separation from Paul Rudd, but nonetheless, I wanted to share some of the work I’ve been doing with Spiros on Quantum TiqTaqToe.
What is Quantum TiqTaqToe?
Evert van Nieuwenburg, the creator of Quantum TiqTaqToe whom I also collaborated with, goes in depth about how the game works here, but I will give a short rundown. The general idea is that there is now a split move, where you can put an ‘X’ in two different squares at once — a Schrödinger’s X, if you will. When the board has no more empty squares, the X randomly ‘collapses’ into one of the two squares with equal probability. The game ends when there are three real X’s or three real O’s in a row, just as in regular tic-tac-toe. Depending on the mode you are playing, you might also be able to entangle your X’s with your opponent’s O’s. You can get a better sense of all this by actually playing the game here.
My goal was to find out who wins when both players play optimally. For instance, in normal tic-tac-toe, it is well-known that the first X should go in the middle of the board, and if player O counters successfully, the game should end in a tie. Is the outcome of Quantum TiqTaqToe, too, predetermined to end in a tie if both players play optimally? And, if not, what is the best first move for player X? I sought to answer these questions through the power of computation.
The First Attempt
In the following section, I refer to a ‘game state’ as any unique arrangement of X’s and O’s on a board. The ‘empty game state’ simply means an empty board. ‘Traversing’ through a certain game state means that, at some point in the game, that game state occurs. So, for example, every game traverses through the empty game state, since every game starts with an empty board.
In order to solve the unsolved, one must first solve the solved. As such, my first attempt was to create an algorithm that would figure out the best move to play in regular tic-tac-toe. This first attempt was rather straightforward, and I will explain it here:
Essentially, I developed a model using what is known as “reinforcement learning” to determine the best next move given a certain game state. Here is how it works: To track which set of moves are best for player X and player O, respectively, every game state is assigned a value, initially 0. When a game ends, these values are updated to reflect who won. The more games are played, the better these values reflect the sequence of moves that X and O must make to win or tie. To train this model (machine learning parlance for the algorithm that updates the values/parameters mentioned above), I programmed the computer to play randomly chosen moves for X and O, until the game ended. If, say, player X won, then the value of every game state traversed was increased by 1 to indicate that X was favored. On the other hand, if player O won, then the value of every game state traversed was decreased by 1 to indicate that O was favored. Here is an example:

Let’s say that this is the first iteration that the model is trained on. Then, the next time the model sees this game state,

it will recognize that X has an advantage. In the same vein, the model now also thinks that the empty game state is favorable towards X, since, in the one game that was played, when the empty game state was traversed, X won.
If we run these randomized games enough times (I ran ten million iterations), every move in every game state has most likely been made, which means that the model is able to give a meaningful evaluation for any game state. However, there is one major problem with this approach, in that the model only indicates who is favored when they make a random move, not when they make the best move. To illustrate this, let’s examine the following game state:

Here, player O has two options: they can win the game by putting their O on the bottom center square, or lose the game by putting it on the right center square. Any seasoned tic-tac-toe player would make the right move in this scenario, and win the game. However, since the model trains on random moves, it thinks that player O will win half the time and lose half the time. Thus, to the model, this game state is not favorable to either player, when in reality it is absolutely favored towards O.&
During my first meeting with Spiros and Evert, they pointed out this flaw in my model. Evert suggested that I study up on something called a minimax algorithm, which circumvents this flaw, and apply it to tic-tac-toe. This set me on the next step of my journey.
Enter Minimax
The content of this section takes inspiration from this article.
In the minimax algorithm, the two players are known as the ‘maximizer’ and the ‘minimizer’. In the case of tic-tac-toe, X would be the maximizer and O the minimizer. The maximizer’s goal is to maximize their score, while the minimizer’s goal is to minimize their score. In tic-tac-toe, the minimax algorithm is implemented so that a win by X is a score of +1, a win by O is a score of -1, and a tie is simply 0. So X, seeking to maximize their score, would want to win, which makes sense.
Now, if X wanted to maximize their score through some move, they would have to consider O’s move, who would try to minimize the score. But before O makes their move, they would have to consider X’s next move. This creates a sort of back-and-forth, recursive dynamic in the minimax algorithm. In order for either player to make the best move, they would have to go through all possible moves they can make, and all possible moves their opponent can make after that, and so on and so forth. Here is a relatively simple example of the minimax algorithm at work:

Let’s start from the top. X has three possible moves they can make, and evaluates each of them.
In the leftmost branch, the result is either -1 or 0, but which is the real score? Well, we expect O to make their best move, and since they are trying to minimize the score, we expect them to choose the ‘-1’ case. So we can say that this move results in a score of -1.
In the middle branch, the result is either 1 or 0, and, following the same reasoning as before, O chooses the move corresponding to the minimal score, resulting in a score of 0.
Finally, the last branch results in X winning, so the score is +1.
Now, X can finally choose their best move, and in the interest of maximizing the score, places their X on the bottom right square. Intuitively, this makes sense because it was the only move that wins the game for X outright.
Great, but what would a minimax algorithm look like in Quantum Tiqtaqtoe?
Enter Expecti-Minimax
Expectiminimax contains the same core idea as minimax, but something interesting happens when the game board collapses. The algorithm can’t know for sure what the board will look like after collapse, so all it can do is calculate an expected value of the result (hence the name). Let’s look at an example:
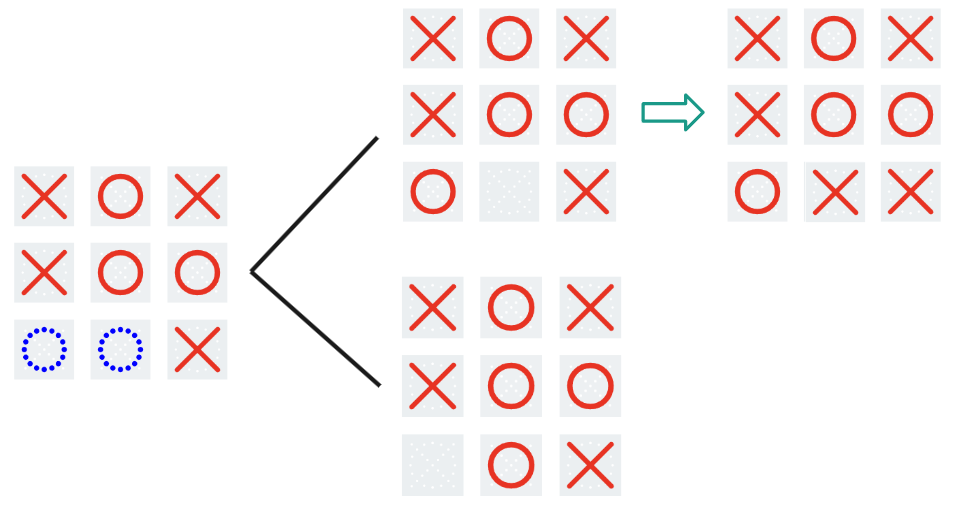
Here, collapse occurs, and one branch (top) results in a tie, while the other (bottom) results in O winning. Since a tie is equal to 0 and an O win is equal to -1, the algorithm treats the score as

Solving the Game
Using the expecti-minimax algorithm, I effectively ‘solved’ the minimal and moderate versions of quantum tiqtaqtoe. However, even though the algorithm will always show the best move, the outcome from game to game might not be the same due to the inherent element of randomness. The most interesting of all my discoveries was probably the first move that the algorithm suggests for X, which I was able to make sense of both intuitively and logically. I challenge you all to find it! (Hint: it is the same for both the minimal and moderate versions.)
It turns out that when X plays optimally, they will always win the minimal version no matter what O plays. Meanwhile, in the moderate version, X will win most of the time, but not all the time. The probability distribution is as follows:

Having satisfied my curiosity (for now), I’m looking forward to creating a new game of my own: 4 by 4 quantum tic-tac-toe. Currently, I am working on an algorithm that will give the best move, but since a 4×4 board is almost two times larger than a 3×3 board, the computational runtime of an expectiminimax algorithm would be far too large. As such, I am exploring the use of heuristics, which is sort of what the human mind uses to approach a game like tic-tac-toe. Because of this reliance on heuristics, there is no longer a guarantee that the algorithm will always make the best move, making this new adventure all the more mysterious and captivating.
Comments