Over the last year or so, the machine learning wave has really been sweeping through the field of condensed matter physics. Machine learning techniques have been applied to condensed matter physics before, but very sparsely and with little recognition. These days, I guess (partially) due to the general machine learning and AI hype, the amount of such studies skyrocketed (I admit to contributing to that..). I’ve been keeping track of this using the arXiv and Twitter (@Evert_v_N), but you should know about this website for getting an overview of the physics & machine learning papers: https://physicsml.github.io/pages/papers.html.
This effort of applying machine learning to physics is a serious attempt at trying to understand how such tools could be useful in a variety of ways. It isn’t very hard to get a neural network to learn ‘something’ from physics data, but it is really hard to find out what – and especially how – the network does that. That’s why toy cases such as the Ising model or the Kosterlitz-Thouless transition have been so important!
When you’re keeping track of machine learning and AI developments, you soon realize that there are examples out there of amazing feats. Being able to generate photo-realistic pictures given just a sentence. e.g. “a brown bird with golden speckles and red wings is sitting on a yellow flower with pointy petals”, is (I think..) pretty cool. I can’t help but wonder if we’ll get to a point where we can ask it to generate “the groundstate of the Heisenberg model on a Kagome lattice of 100×100”…
Another feat I want to mention, and the main motivation for this post, is that of being able to encode words as vectors. That doesn’t immediately seem like a big achievement, but it is once you want to have ‘similar’ words have ‘similar’ vectors. That is, you intuitively understand that Queen and King are very similar, but differ basically only in gender. Can we teach that to a computer (read: neural network) by just having it read some text? Turns out we can. The general encoding of words to vectors is aptly named ‘Word2Vec’, and some of the top algorithms that do that were introduced here (https://arxiv.org/abs/1301.3781) and here (https://arxiv.org/abs/1310.4546). The neat thing is that we can actually do arithmetics with these words encoded as vectors, so that the network learns (with no other input than text!):
- King – Man + Woman = Queen
- Paris – France + Italy = Rome
In that spirit, I wondered if we can achieve the same thing with physics jargon. Everyone knows, namely, that “electrons + two dimensions + magnetic field = Landau levels”. But is that clear from condensed matter titles?
Try it yourself
If you decide at this point that the rest of the blog is too long, at least have a look here: everthemore.pythonanywhere.com or skip to the last section. That website demonstrates the main point of this post. If that sparks your curiosity, read on!
This post is mainly for entertainment, and so a small disclaimer is in order: in all of the results below, I am sure things can be improved upon. Consider this a ‘proof of principle’. However, I would be thrilled to see what kind of trained models you can come up with yourself! So for that purpose, all of the code (plus some bonus content!) can be found on this github repository: https://github.com/everthemore/physics2vec.
Harvesting the arXiv
The perfect dataset for our endeavor can be found in the form of the arXiv. I’ve written a small script (see github repository) that harvests the titles of a given section from the arXiv. It also has options for getting the abstracts, but I’ll leave that for a separate investigation. Note that in principle we could also get the source-files of all of these papers, but doing that in bulk requires a payment; and getting them one by one will 1) take forever and 2) probably get us banned.
Collecting all this data of the physics:cond-mat subsection took right about 1.5 hours and resulted in 240737 titles and abstracts (I last ran this script on November 20th, 2017). I’ve filtered them by year and month, and you can see the result in Fig.1 below. Seems like we have some catching up to do in 2017 still (although as the inset shows, we have nothing to fear. November is almost over, but we still have the ‘getting things done before x-mas’ rush coming up!).
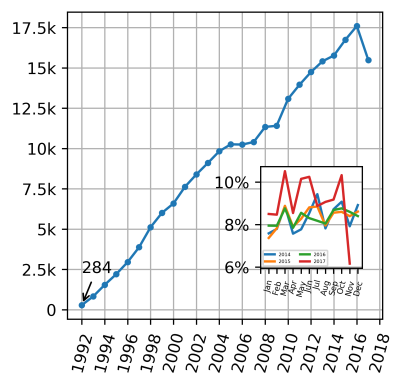
Figure 1: The number of papers in the cond-mat arXiv section over the years. We’re behind, but the year isn’t over yet! (Data up to Nov 20th 2017)
Analyzing n-grams
After tidying up the titles (removing LaTeX, converting everything to lowercase, etc.), the next thing to do is to train a language model on finding n-grams. N-grams are basically fixed n-word expressions such as ‘cooper pair’ (bigram) or ‘metal insulator transition’ (trigram). This makes it easier to train a Word2Vec encoding, since these phrases are fixed and can be considered a single word. The python module we’ll use for Word2Vec is gensim (https://radimrehurek.com/gensim/), and it conveniently has phrase-detection built-in. The language model it builds reports back to us the n-grams it finds, and assigns them a score indicating how certain it is about them. Notice that this is not the same as how frequently it appears in the dataset. Hence an n-gram can appear fewer times than another, but have a higher certainty because it always appears in the same combination. For example, ‘de-haas-van-alphen’ appears less than, but is more certain than, ‘cooper-pair’, because ‘pair’ does not always come paired (pun intended) with ‘cooper’. I’ve analyzed up to 4-grams in the analysis below.
I can tell you’re curious by now to find out what some of the most certain n-grams in cond-mat are (again, these are not necessarily the most frequent), so here are some interesting findings:
- The most certain n-grams are all surname combo’s, Affleck-Kennedy-Lieb-Tasaki being the number 1. Kugel-Khomskii is the most certain 2-name combo and Einstein-Podolksi-Rosen the most certain 3-name combo.
- The first certain non-name n-gram is a ‘quartz tuning fork’, followed by a ‘superconducting coplanar waveguide resonator’. Who knew.
- The bigram ‘phys. rev.’ and trigram ‘phys. rev. lett.’ are relatively high up in the confidence lists. These seem to come from the “Comment on […]”-titles on the arXiv.
- I learned that there is such a thing as a Lefschetz thimble. I also learned that those things are called thimbles in English (we (in Holland) call them ‘finger-hats’!).
In terms of frequency however, which is probably more of interest to us, the most dominant n-grams are Two-dimensional, Quantum dot, Phase transition, Magnetic field, One dimensional and Bose-Einstein (in descending order). It seems 2D is still more popular than 1D, and all in all the top n-grams do a good job at ‘defining’ condensed matter physics. I’ll refer you to the github repository code if you want to see a full list! You’ll find there a piece of code that produces wordclouds from the dominant words and n-grams too, such as this one:
For fun though, before we finally get to the Word2Vec encoding, I’ve also kept track of all of these as a function of year, so that we can now turn to finding out which bigrams have been gaining the most popularity. The table below shows the top 5 n-grams for the period 2010 – 2016 (not including 2017) and for the period 2015 – Nov 20th 2017.
|
2010-2016 |
2015 – November 20th 2017 |
| Spin liquids | Topological phases & transitions |
| Weyl semimetals | Spin chains |
| Topological phases & transitions | Machine learning |
| Surface states | Transition metal dichalcogenides |
| Transition metal dichalcogenides | Thermal transport |
| Many-body localization | Open quantum systems |
Actually, the real number 5 in the left column was ‘Topological insulators’, but given number 3 I skipped it. Also, this top 5 includes a number 6 (!), which I just could not leave off given that everyone seems to have been working on MBL. If we really want to be early adopters though, taking only the last 1.8 years (2015 – now, Nov 20th 2017) in the right column of the table shows some interesting newcomers. Surprisingly, many-body localization is not even in the top 20 anymore. Suffice it to say, if you have been working on anything topology-related, you have nothing to worry about. Machine learning is indeed gaining lots of attention, but we’ve yet to see if it doesn’t go the MBL-route (I certainly don’t hope so!). Quantum computing does not seem to be on the cond-mat radar, but I’m certain we would find that high up in the quant-ph arXiv section.
CondMat2Vec
Alright, finally time to use some actual neural networks for machine learning. As I started this post, what we’re about to do is try to train a network to encode/decode words into vectors, while simultaneously making sure that similar words (by meaning!) have similar vectors. Now that we have the n-grams, we want the Word2Vec algorithm to treat these as words by themselves (they are, after all, fixed combinations).
In the Word2Vec algorithm, we get to decide the length of the vectors that encode words ourselves. Larger vectors means more freedom in encoding words, but also makes it harder to learn similarity. In addition, we get to choose a window-size, indicating how many words the algorithm will look ahead to analyze relations between words. Both of these parameters are free for you to play with if you have a look at the source code repository. For the website everthemore.pythonanywhere.com, I’ve uploaded a size 100 with window-size 10 model, which I found to produce sensible results. Sensible here means “based on my expectations”, such as the previous example of “2D + electrons + magnetic field = Landau levels”. Let’s ask our network some questions.
First, as a simple check, let’s see what our encoding thinks some jargon is similar to:
- Superconductor ~ Superconducting, Cuprate superconductor, Superconductivity, Layered superconductor, Unconventional superconductor, Superconducting gap, Cuprate, Weyl semimetal, …
- Majorana ~ Majorana fermion, Majorana mode, Non-abelian, Zero-energy, braiding, topologically protected, …
It seems we could start to cluster words based on this. But the real test comes now, in the form of arithmetics. According to our network (I am listing the top two choices in some cases; the encoder outputs a list of similar vectors, ordered by similarity):
- Majorana + Braiding = Non-Abelian
- Electron + Hole = Exciton, Carrier
- Spin + Magnetic field = Magnetization, Antiferromagnetic
- Particle + Charge = Electron, Charged particle
And, sure enough:
- 2D + electrons + magnetic field = Landau level, Magnetoresistance oscillation
The above is just a small sample of the things I’ve tried. See the link in the try it yourself section above if you want to have a go. Not all of the examples work nicely. For example, neither lattice + wave nor lattice + excitation nor lattice + force seem to result in anything related to the word ‘phonon’. I would guess that increasing the window size will help remedy this problem. Even better probably would be to include abstracts!
Outlook
I could play with this for hours, and I’m sure that by including the abstracts and tweaking the vector size (plus some more parameters I haven’t even mentioned) one could optimize this more. Once we have an optimized model, we could start to cluster the vectors to define research fields, visualizing the relations between n-grams (both suggestions thanks to Thomas Vidick and John Preskill!), and many other things. This post has become rather long already however, and I will leave further investigation to a possible future post. I’d be very happy to incorporate anything cool you find yourselves though, so please let me know!
Comments